
A scalable memory-centric algorithm that dynamically extracts and retrieves key conversational facts—delivering 26% relative accuracy gains over OpenAI on the LOCOMO benchmark, with 91% lower p95 latency and 90% fewer tokens.
If you've built anything with LLMs, you know this problem: As conversations grow, the model will start dropping context, reasoning degrades, and token costs spike. @zentry.gg fixes this! Zentry extracts and organizes only what's important, turning relevant exchanges into dynamic memory or even into a graph when deeper reasoning is needed.
Benchmarking Zentry
AI systems today forget key facts over extended interactions, breaking context and eroding trust. Simply enlarging LLM context windows only delays the problem—models get slower, costlier, and still overlook critical details.
Zentry addresses this problem head-on with a scalable memory architecture that dynamically extracts, consolidates, and retrieves important information from conversations. An enhanced variant, Zentry, layers in a graph-based store to capture richer, multi-session relationships.
On the LOCOMO benchmark, Zentry consistently outperforms six leading memory approaches, achieving:
By making persistent, structured memory practical at scale, Zentry paves the way for AI agents that don't just react, but truly remember, adapt, and collaborate over time.
Under the hood
A two-phase memory pipeline that extracts, consolidates, and retrieves only the most salient conversational facts—enabling scalable, long-term reasoning.
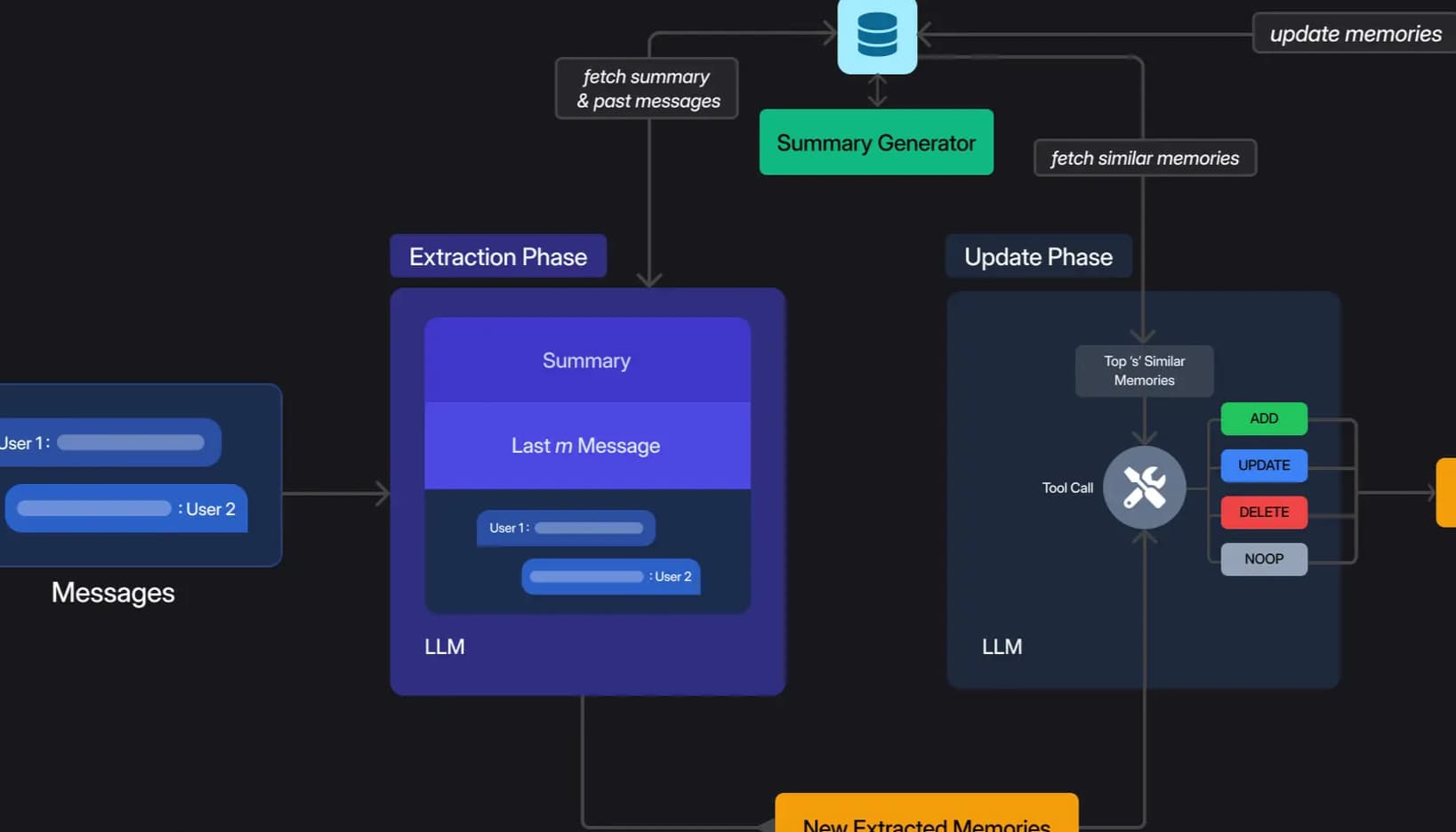
Zentry's pipeline consists of two phases—Extraction and Update—ensuring only the most relevant facts are stored and retrieved, minimizing tokens and latency.
Extraction Phase
In the Extraction Phase, the system ingests three context sources—the latest exchange, a rolling summary, and the m most recent messages—and uses an LLM to extract a concise set of candidate memories. A background module refreshes the long-term summary asynchronously, so inference never stalls.
Update Phase
In the Update Phase, each new fact is compared to the top s similar entries in the vector database. The LLM then chooses one of four operations:
These steps keep the memory store coherent, non-redundant, and instantly ready for the next query.

Work in Progress 🚧
The rest of this article is currently being written and will be continued soon. Stay tuned for more detailed insights into Zentry's implementation, performance benchmarks, and real-world applications.